concurrency
In computer science, concurrency refers to the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the final outcome. This allows for parallel execution of the concurrent units, which can significantly improve overall speed of the execution in multi-processor and multi-core systems. In more technical terms, concurrency refers to the decomposability property of a program, algorithm, or problem into order-independent or partially-ordered components or units.
A number of mathematical models have been developed for general concurrent
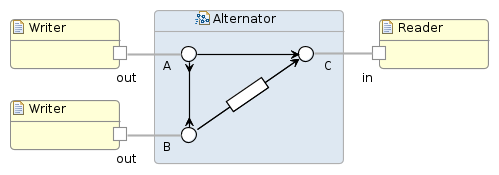
computation including Petri nets, process calculi, the Parallel Random Access Machine model, the Actor model and the Reo Coordination Language.
As Leslie Lamport (2015) notes, “While concurrent program execution had been considered for years, the computer science of concurrency began with Edsger Dijkstra’s seminal 1965 paper that introduced the mutual exclusion problem. The ensuing decades have seen a huge growth of interest in concurrency—particularly in distributed systems. Looking back at the origins of the field, what stands out is the fundamental role played by Edsger Dijkstra”.
Because computations in a concurrent system can interact with each other while being executed, the number of possible execution paths in the system can be extremely large, and the resulting outcome can be indeterminate. Concurrent use of shared resources can be a source of indeterminacy leading to issues such as deadlocks, and resource starvation.
Design of concurrent systems often entails finding reliable techniques for coordinating their execution, data exchange, memory allocation, and execution scheduling to minimize response time and maximise throughput.
Concurrency theory has been an active field of research in theoretical computer science. One of the first proposals was Carl Adam Petri‘s seminal work on Petri Nets in the early 1960s. In the years since, a wide variety of formalisms have been developed for modeling and reasoning about concurrency.
Concurrent programming encompasses programming languages and algorithms used to implement concurrent systems. Concurrent programming is usually considered to be more general than parallel programming because it can involve arbitrary and dynamic patterns of communication and interaction, whereas parallel systems generally have a predefined and well-structured communications pattern. The base goals of concurrent programming include correctness, performance and robustness. Concurrent systems such as Operating systems and Database management systems are generally designed to operate indefinitely, including automatic recovery from failure, and not terminate unexpectedly. Some concurrent systems implement a form of transparent concurrency, in which concurrent computational entities may compete for and share a single resource, but the complexities of this competition and sharing are shielded from the programmer.
Because they use shared resources, concurrent systems in general require the inclusion of some kind of arbiter somewhere in their implementation (often in the underlying hardware), to control access to those resources. The use of arbiters introduces the possibility of indeterminacy in concurrent computation which has major implications for practice including correctness and performance. For example, arbitration introduces unbounded nondeterminism which raises issues with model checking because it causes explosion in the state space and can even cause models to have an infinite number of states. Some concurrent programming models include coprocesses and deterministic concurrency. In these models, threads of control explicitly yield their timeslices, either to the system or to another process.
parallelism
Parallel computing is a type of computation in which many calculations or the execution of processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has been employed for many years, mainly in high-performance computing, but interest in it has grown lately due to the physical constraints preventing frequency scaling. As power consumption (and consequently heat generation) by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
Parallel computing is closely related to concurrent computing—they are frequently used together, and often conflated, though the two are distinct: it is possible to have parallelism without concurrency (such as bit-level parallelism), and concurrency without parallelism (such as multitasking by time-sharing on a single-core CPU).

In parallel computing, a computational task is typically broken down in several, often many, very similar subtasks that can be processed independently and whose results are combined afterwards, upon completion. In contrast, in concurrent computing, the various processes often do not address related tasks; when they do, as is typical in distributed computing, the separate tasks may have a varied nature and often require some inter-process communication during execution. Parallel computers can be roughly classified according to the level at which the hardware supports parallelism, with multi-core and multi-processor computers having multiple processing elements within a single machine, while clusters, MPPs, and grids use multiple computers to work on the same task. Specialized parallel computer architectures are sometimes used alongside traditional processors, for accelerating specific tasks. In some cases parallelism is transparent to the programmer, such as in bit-level or instruction-level parallelism, but explicitly parallel algorithms, particularly those that use concurrency, are more difficult to write than sequential ones, because concurrency introduces several new classes of potential software bugs, of which race conditions are the most common. Communication and synchronization between the different subtasks are typically some of the greatest obstacles to getting good parallel program performance.
In the video below are shown the differences between concurrency and parallelism:
distributed computing
Distributed computing is a field of computer science that studies distributed systems. A distributed system is a model in which components located on networked computers communicate and coordinate their actions by passing messages. The components interact with each other in order to achieve a common goal. Three significant characteristics of distributed systems are: concurrency of components, lack of a global clock, and independent failure of components. Examples of distributed systems vary from SOA-based systems to massively multiplayer online games to peer-to-peer applications.
A computer program that runs in a distributed system is called a distributed program, and distributed programming is the process of writing such programs. There are many alternatives for the message passing mechanism, including pure HTTP, RPC-like connectors and message queues. A goal and challenge pursued by some computer scientists and practitioners in distributed systems is location transparency; however, this goal has fallen out of favor in industry, as distributed systems are different from conventional non-distributed systems, and the differences, such as network partitions, partial system failures, and partial upgrades, cannot simply be papered over by attempts at transparency. Distributed computing also refers to the use of distributed systems to solve computational problems. In distributed computing, a problem is divided into many tasks, each of which is solved by one or more computers, which communicate with each other by message passing.
Reasons for using distributed systems and distributed computing may include:
- The very nature of an application may require the use of a communication network that connects several computers: for example, data produced in one physical location and required in another location.
- There are many cases in which the use of a single computer would be possible in principle, but the use of a distributed system is beneficial for practical reasons. For example, it may be more cost-efficient to obtain the desired level of performance by using a cluster of several low-end computers, in comparison with a single high-end computer. A distributed system can provide more reliability than a non-distributed system, as there is no single point of failure. Moreover, a distributed system may be easier to expand and manage than a monolithic uniprocessor system.
